Cosnova ist ein führender europäischer Kosmetikanbieter und Mengenmarktführer in Deutschland mit verschiedenen Produktkategorien und Marken – u.a. den Kosmetikserien Essence und Catrice die überwiegend über Drogerie Discounter vertrieben werden.
Cosnova GmbH
Daten konsolidieren aus mehr als 60 Quellformaten
Data Vault für Cosnova GmbH
Kunde
Cosnova GmbH
Branche: Kosmetikindustrie
Firmensitz: Sulzbach (Taunus), Hessen
Technologien
- Data Vault 2.0
- Python
- PostgreSQL
- Tableau
- Azure Cloud
- Grafana
Beratungsthemen
- Architektur einer modernen Data Warehouse Plattform
- Datenmodellierung Data Vault 2.0
- Implementierung und Betrieb robuster DWH Bewirtschaftungsstrecken
- Coaching bei der Erstellung von Visualisierungen mit Tableau
Quantifzierbare Benefits
- über 140 Quellobjekte und Bewirtschaftungsprozesse
- über 60 verschiedene Quelldatenformate
- 9 Tableau Reports bestehend aus insgesamt 50 Dashboards
- 1 Grafana Monitoring Dashboard
Einsatz einer Data Vault Architektur und eines Python / PostgreSQL basierten Implementierungsframeworks, um agil, flexibel und effizient Daten aus verschiedensten Quellen auf einer zentralen BI-Plattform bereitzustellen.
Allgemeine Beschreibung des Kunden
Die Aufgaben
An zentraler Stelle die Verkaufszahlen bereitstellen, welche von den diversen Online-Shops und Drogerieketten gemeldet werden. Des Weiteren den Erfolg von Online-Marketingkampagnen auf den diversen Plattformen zentral verfügbar machen.
Die Herausforderung
Die sehr hohe Anzahl an externen Datenquellen führt aufgrund fehlender Standards zu einer großen Varianz bezüglich der Inhalte, Formate und Datenqualität in den gelieferten Daten. Sowohl die Extraktion als auch die Korrektur erfordern ein hohes Maß an Flexibilität in der Datenmodellierung und bei der Implementierung der Ladestrecken.
Lösung – Ergebnisse – Highlights
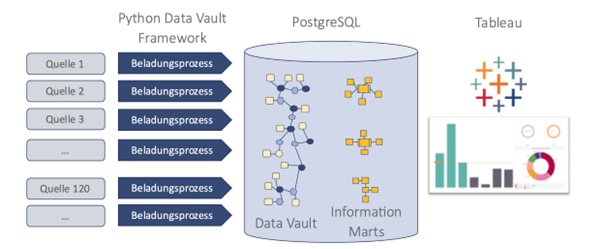
Lösung
Für die Integration und Datenbereitstellung wurde eine Data Warehouse Plattformt mit folgenden zentralen Methoden und Technologien aufgebaut:
- Architektur und Modellierung: Data Vault 2.0
- Datenbank: PostgreSQL
- Implementierung Beladung: Python basiertes Framework mit entkoppelten quellfokussierten Modulen, die jeweils als eigene Docker Image für die Ausführung bereitgestellt werden
- Azure Cloud basierte Ausführungsplattform: mit Docker/Kubernetes, Argo als Scheduler und Grafana Dashboard für die Prozessüberwachung
- Datenzugriff und Präsentation: Tableau
Die Dokumentation erfolgt in dem schon beim Kunden vorhandenen Confluence. Für die Projekt- und Aufgabensteuerung wird Jira eingesetzt.
Ergebnisse
Dank der Data Vault Architektur und Modellierung können die verschiedenen eingehenden Datenstrukturen problemlos in das Data Warehouse geladen werden. Die notwendigen Bereinigungsschritte und Transformationen zur Angleichung erfolgt beim Übergang in den zentralen Business Vault: Von dort werden die nun gleichförmigen Daten mit Produktinformationen angereichert und Tableau zur Visualisierung übergeben.
Die Implementierung in Python ermöglicht die Extraktion von Daten aus beliebigen Formaten und Strukturen. So war es möglich auch Dateien zu parsen, in denen die Daten pivotisiert dargestellt sind, Spaltenpositionen von Monat zu Monat wechseln oder die Ursprungsposition der Daten in einer Matrix je nach Monat, Marke oder Shop verschieden ist.
Die gleiche Flexibilität gilt für die Methoden der technischen Validierung der Formate und die Bestimmung, welche Daten als aktuell geliefert angesehen werden.
Die Data Vault Grundprinzipien bzgl. der zu speichernden Metadaten und der rigorosen Historisierung waren mehrfach eine wesentliche Stütze bei der effizienten Suche nach der Ursache von Datenfehlern. Ebenso konnte dank der strikten Trennung von Raw Vault und Business Vault sehr flexibel und zügig auf spät erkannte Datenqualitätsprobleme reagiert werden.
Highlights
- Erste Datenquelle Mitte 2020 produktiv in Betrieb
- 160 Datenquellobjekte mit mehr als 70 Datenformaten angebunden
- Störungen beschränken sich auf Datenformatfehler
- Teamgröße für Implementierung und Betrieb
- 1 Product Owner
- 2 Modellierer und Job Entwickler (3 in der Hochphase)
- 1 Tableau Berater und Data Quality Prüfer
- 0,5 DevOps Engineer
- Python Framework für Data Vault Bewirtschaftung aufgebaut
- Integration einer neuen Quelle: 1-2 Tage, je nach Komplexität des Formats und Datenqualität (inklusive Dokumentation und Tests)
- Keine Lizenzkosten für die Kernprodukte (Datenbank, Implementierungswerkzeug)
- Skalierbarkeit durch cloud-basierte Infrastruktur
Aufgabe von cimt
Als Spezialist für Data Management mit mehr als 24 Jahre Erfahrung, wurden wir für folgende Aufgaben herangezogen:
- Bestimmung und Ausgestaltung der Architektur
- Auswahl der Technologie für die Datenhaltung und Implementierung der Bewirtschaftung
- Beratung bei der Auswahl der Betriebsplattform
- Gestaltung des Entwicklungsprozesses (Analyse, Design, Implementierung, Dokumentation)
- Design und Implementierung des Beladungsframeworks in Python
- Datenanalyse, Modellierung und Implementierung von Beladungsstrecken
- Datenqualitätssicherung
- Beratung und Gestaltung der Datenpräsentation in Tableau
cimt Python ETL Framework
- Framework zur Beladung von Data Vault basierten Data Warehouses
- Inklusive Implementierungsmuster und SQL Code Generatoren für alle gängigen Data Vault Tabellenstereotypen
- Stützt sich auf das cimt Job-Instance-Framework für das Ausführungs-Monitoring, Inkrementverwaltung und Restart-Festigkeit
- Dank Python hochflexibel bezüglich der Zugriffsprotokolle auf die Quellsysteme und der eingehenden Datenformate
WEITERE BUSINESS CASES