
Aufbau eines Data Quality Frameworks
Identifikation von Abweichungen und Fehlern in vorhandenen Datenbeständen

In Data Warehouse Projekten entstehen viele Daten und Abhängigkeiten. Aus den verschiedensten Fachbereichen eines Unternehmens laufen die Daten aus unterschiedlichsten Datenquellen und Formaten im Data Warehouse zusammen. Bevor diese jedoch im Data Warehouse ankommen, ist es meist notwendig diese in, manchmal mehr oder weniger, komplexen ETL-Prozessen (Extract-Transform-Load) für das Data Warehouse aufzubereiten, damit diese dann später in Tabellen, Views, Reports, Excels, CSVs und etlichen anderen Formaten bereitgestellt werden können.
Innerhalb dieses Bereitstellungsprozesses kann es dazu kommen, dass Daten aufgrund der Komplexität verändert, verloren, verdoppelt oder auf andere Weise die Integrität verlieren können. Aus diesem Grunde sollten in den Bereitstellungsprozess bereits Prüfungen eingebaut werden, die einen solchen Integritätsverlust zu erkennen und zu vermeiden in der Lage sind.
Hier ist es sehr sinnvoll, mit Hilfe einer Testgetriebenen Entwicklung die Prozesse zu erstellen, um so die Integrität der Daten sicherstellen zu können. Um den Kollegen zu zitieren: “Bei dieser Vorgehensweise wird der Tests auf der Basis der Anforderungen geschrieben statt auf Basis der Code-Logik.”.
Doch nicht immer ist es möglich mit einer Testgetriebenen Entwicklung die Daten im Vorfeld zu verifizieren und zu manipulieren. Wie sieht es außerdem mit Daten aus, die in der Basis bzw. dem Quellsystem korrigiert werden müssen und nicht erst im Datenfluss? Eine fehlerhafte Rufnummer mag den ETL-Prozess in keiner Weise stören, ist für den Ablauf von Geschäftsprozessen aber von entscheidender Bedeutung.
Anforderung
Um diesem Problem zu begegnen, wurden die folgenden Wünsche und Ziele formuliert.
Die Integritätsprüfung erfolgt auf finale Daten
Es werden keine Zwischenschritte geprüft. Sollte die Überprüfung eines Zwischenschrittes notwendig sein, so sollte diese in den ETL-Prozess, sinnvollerweise als Testgetriebene Entwicklung, umgesetzt werden.
Dieser Ansatz ermöglicht es, die Überprüfung vollkommen unabhängig der Komplexität des ETL-Prozesses zu gestalten und durchzuführen.
Pro Abfrage/Prüfung wird nur auf einen Fehler geprüft
Ganz getreu dem Motto “Keep it short and simple” (KISS) sollte eine Abfrage auch nur einen Fehler überprüfen. Das stellt in den meisten Fällen sicher, dass die Abfrage auch kurz und verständlich gehalten werden kann, was für den nächsten Punkt wichtig ist.
Abfragen sollten möglichst einfach sein
Schon die Einschränkung auf die Regel “1 Prüfung = 1 Fehler” erzwingt eine gewisse Einfachheit einer Abfrage. Idealerweise wird auf die Nutzung von Joins oder Aggregationen in der Prüfung verzichtet.
Manchmal ist es nicht möglich für die Prüfung eine einfache Abfrage zu gestalten. Sollte jedoch eine Abfrage komplizierter und damit unverständlich werden, so ist die Abfrage und damit ihre Funktionalität auf ihre Sinnhaftigkeit zu prüfen. Wenn diese Prüfung ergibt, dass die Abfrage genau so gebaut werden muss, ist dies auf jeden Fall zu begründen und zu dokumentieren.
Es werden nur Fehler ausgegeben
Eine Liste mit Datensätzen anzuzeigen, die vollkommen in Ordnung sind, ist weder sinnvoll noch notwendig.
Es wird nur die ID des Datensatzes ausgegeben
Es ist nicht notwendig, die gesamte Datenzeile auszugeben. Die Ausgabe der ID des Datensatzes ermöglicht bereits eine eindeutige Identifikation mit dem Originären Datensatz. Der Join der Error-Tabelle mit den Originaldaten liefert alle notwendigen Daten zur Sichtung und Korrektur der Daten und bietet die größtmögliche Flexibilität bei der Darstellung und Auswertung.
Die Benachrichtigung ist für alle verständlich
Die Prüfung soll für Menschen und nicht für Algorithmen gemacht sein. Hier sollte ein verständlicher Hinweis auf den Fehler dem Endanwender angeboten werden, damit dieser ohne ein tieferes technisches Verständnis sofort erkennen kann, was das Problem ist.
Die Benachrichtigung enthält idealerweise eine Handlungsanweisung
Das erkennen eines Problems bedeutet leider nicht immer, dass auch bekannt ist, was getan werden muss. Hier ist es empfehlenswert eine Handlungsanweisung mitzugeben, was der Benutzer tun kann, um diesen Fehler beheben zu können.
Es ist definiert, wer den Fehler prüfen/beheben kann
Unterschiedlichste Fehler können von unterschiedlichsten Personen oder Abteilungen korrigiert werden müssen. So ist die Änderung einer Abrechnungsart Sache der Buchhaltung, während die Änderung eines Namens die Sache der Personalabteilung ist. Um den Fehler möglichst direkt der richtigen Abteilung zuordnen zu können, ist es erforderlich, diese im Ergebnis zu benennen.
Prüfungen sollten von allen verstanden/beantragt werden können
Auch wenn es Zuviel verlangt wäre, dass ein Endbenutzer eine SQL-Anweisung schreiben oder lesen könnte, so soll die Prüfung dennoch so gestaltet sein, dass jeder Benutzer die Sinnhaftigkeit nachvollziehen und damit überprüfen kann. Wenn dem Endnutzer eine SQL-Anweisung gezeigt wird, sollte dieser idealerweise eine Where-Bedingung lesen und verstehen können. Idealerweise unterstützt man den Leseprozess durch aussagekräftige Kommentarzeilen.
In der anderen Richtung sollte mit dem Endbenutzer eine mögliche Prüfung so formuliert werden, dass sie möglichst ohne Verluste in eine Prüfabfrage umgebaut werden kann.
Die Umsetzung
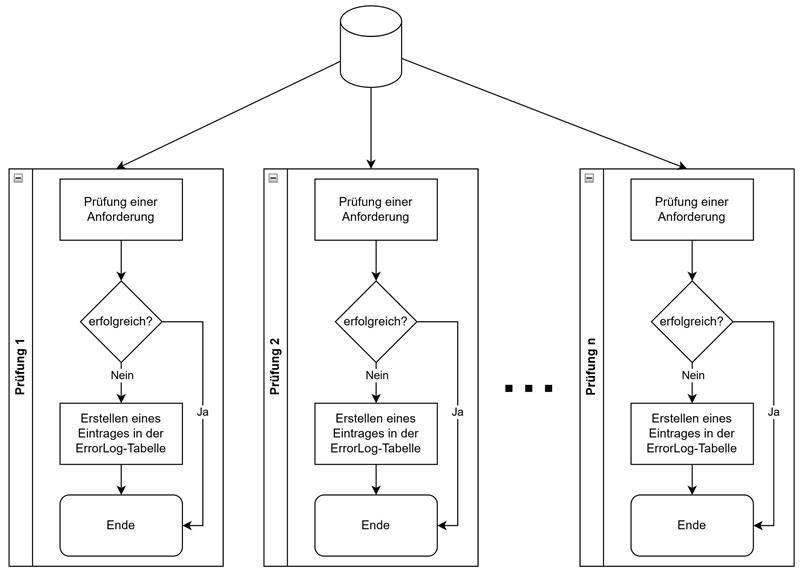
Die Umsetzung lässt sich relativ grob und einfach folgendermaßen beschreiben:
Daten werden aus möglichst einer Quelltabelle gelesen und einer oder mehrerer Prüfungen unterzogen. Sollte eine Prüfung einen Fehler ergeben, so wird die ID des Datensatzes mit einer entsprechenden Beschreibung in einer ErrorLog-Tabelle gespeichert.
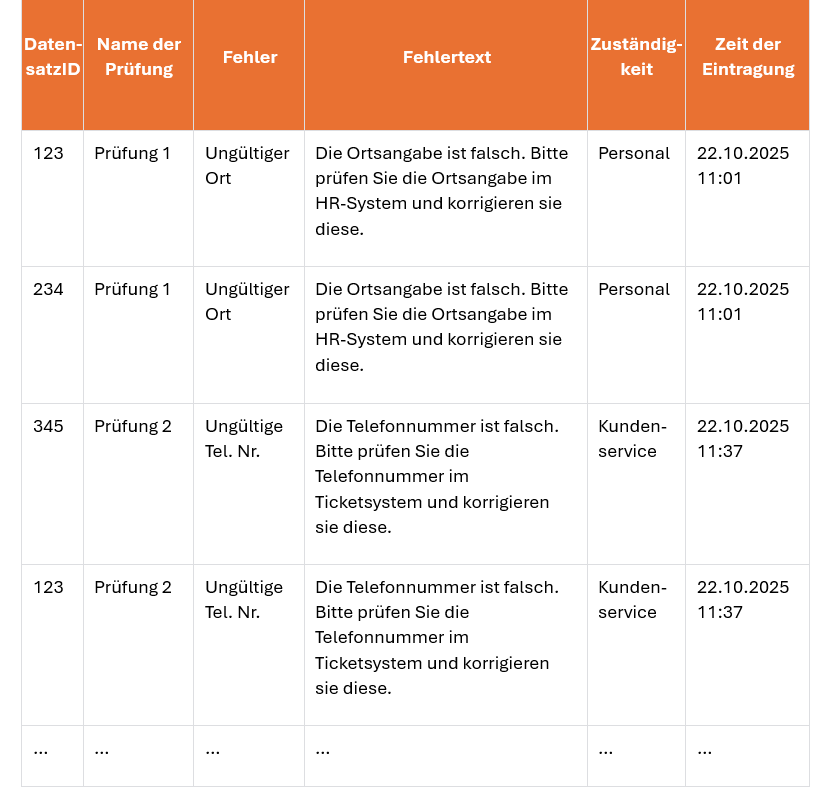
Die ErrorLog-Tabelle nimmt (Beispielhaft) die folgenden Werte auf:
- Eine DatensatzID zur Identifikation des Quelldatensatzes. Dies setzt natürlich voraus, dass der Quelldatensatz mit einer solchen ausgerüstet ist. Es kann sich hier auch um einen selbst definierten Primärschlüssel innerhalb der Tabelle handeln.
- Den Namen der Prüfung – Welche Prüfung führte zu diesem Eintrag.
- Welcher Fehler (Kurzform) meldet diese Prüfung? Hier kann auch überlegt werden, ob es sinnvoll ist, eine Fehlernummer, vielleicht sogar aus einem definierten Fehlerkatalog, als Identifikator zu hinterlegen.
- Der Fehlertext ist ein Text in menschenlesbarer Form, der im Idealfall auch gleich eine konkrete Handlung beschreibt.
- Die Zuständigkeit gibt an, wer diesen Fehler korrigieren kann.
- Die Zeit der Eintragung gibt an, wann dieser Fehler festgestellt wurde.
Möglichkeiten der Nutzung
Sobald die Fehler in der ErrorLog-Tabelle gesichert sind, gibt es nun viele Möglichkeiten, wie damit umgegangen werden kann.
Neben der klassischen Anzeige der Fehler als Report, wäre es denkbar einen Automatismus zu etablieren, der die Fehlermeldungen sortiert, gruppiert und/oder aufbereitet und an die zuständige Stelle z.B. per Email meldet, sobald dieser auftritt.
Sollte die Fehlerbehebung automatisierbar sein, kann ein Prozess getriggert werden, der die Korrektur der Daten im Quellsystem direkt vornehmen kann.
Schulungen für Benutzer der Quellsysteme können direkt auf häufige Fehler abgestimmt werden und somit eine nachhaltige Fehlerbehebungskultur fördern.
Fazit
Auch wenn eine testgetriebene Entwicklung sinnvoll und zu bevorzugen ist, so ist eine nachträgliche Prüfung von Daten manchmal ebenso sinnvoll.
Das hier vorgestellte Data Quality Framework eröffnet, mit seinem Fokus auf Einfachheit, ein breites Anwendungsspektrum und soll Entwicklern wie auch Endanwendern eine unkomplizierte Prüfung, Behebung und Auswertung von Datenfehlern ermöglichen.

