
Das Unified Star Schema
Ein robusteres Datenmodell für nachhaltige Self Service BI

Das Große Versprechen von Analytics und Business Intelligence Plattformen ist Self Service, nach dem Motto: „Unser Tool ist so intuitiv, dass wirklich jeder damit Daten analysieren und visualisieren kann“. Doch die Bedienung kann noch so intuitiv sein – Self Service steht und fällt mit der Datengrundlage bzw. dem Datenmodell.
Auch wenn die BI Tools einfache Möglichkeiten bieten Daten zu kombinieren, erfordert dies oft tiefergehendes Wissen und Fingerspitzengefühl. Ansonsten können Fallstricke warten wie:
Fan Trap: Entsteht bei der Kombination von zwei Tabellen, die eine 1:m Beziehung aufweisen und jeweils Zahlen enthalten. Die Folge ist die Vervielfachung der Zahlen, da mehrere Reihen aus der einen Tabelle auf nur eine Reihe der anderen Tabelle weisen.
Chasm Trap: Entsteht wenn eine Zieltabelle durch die Kombination mit mindestens zwei weiteren Tabellen explodiert – ähnlich wie bei einem kartesischen Produkt. Dieses Problem tritt auf, wenn eine einzelne Zeile in der Zieltabelle gleichzeitig auf mehrere Zeilen in den beiden weiteren Tabellen verweist.
Vernichtung von Daten: Entsteht bei der Kombination von zwei Tabellen, die jeweils nicht alle Schlüssel der anderen Tabelle enthalten. Nur ein Full Outer Join würde ein vollständiges Ergebnisset liefern. Diese Funktion wird allerdings nicht von allen Tools unterstützt.
Bewährter Ansatz der Datenmodellierung
Um die Fachbereiche nicht mit diesen Problemen allein zu lassen wurde bisher auf die Modellierung der Daten nach dem Star Schema von Ralph Kimball gesetzt.
Weitere Gründe für das Star Schema waren begrenzte Rechenleistungen und Speicherplatz früherer Tage. Bei dem Modell werden Dimensionstabellen um eine Faktentabelle angeordnet (Abbildung 1). Aufgrund der Komplexität wird dies meist von Data Engineers vorbereitet.
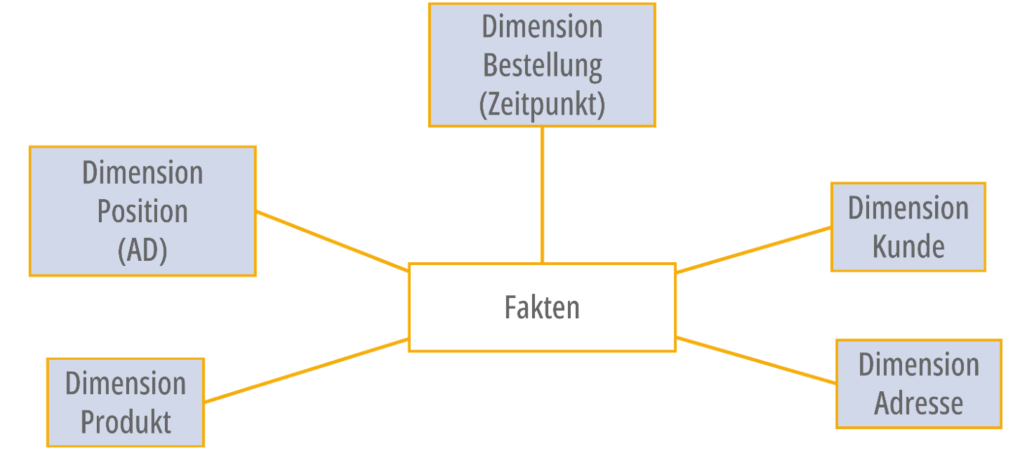
Abbildung 1: Star Schema (eig. Darstellung)
Komplexität und Abhängigkeit
In der Faktentabelle werden die nummerischen Kennzahlen gespeichert sowie die Fremdschlüssel zu den Dimensionstabellen. In den Dimensionstabellen werden die beschreibenden Attribute gespeichert. Dadurch werden die Daten für Fachbereiche durch einfache Joins zwar kombinierbar, ohne auf Probleme wie Chasm oder Fan Trap zu stoßen, allerdings ist die Granularität der Daten durch die Faktentabelle festgelegt. Das bedeutet, dass nur das zusammengebracht werden kann, was bereits modelliert ist.
Neue Fragestellungen würden technische Anpassungen erfordern (z.B. neue Faktentabellen). Dabei sind End User wieder auf die Unterstützung der Data Engineers angewiesen. Das Ergebnis dieser Modellierungsmethode ist, dass es eine Vielzahl an Star Schemas im Unternehmen gibt, was zu Verwirrung und Unübersichtlichkeit führen kann (Abbildung 2).
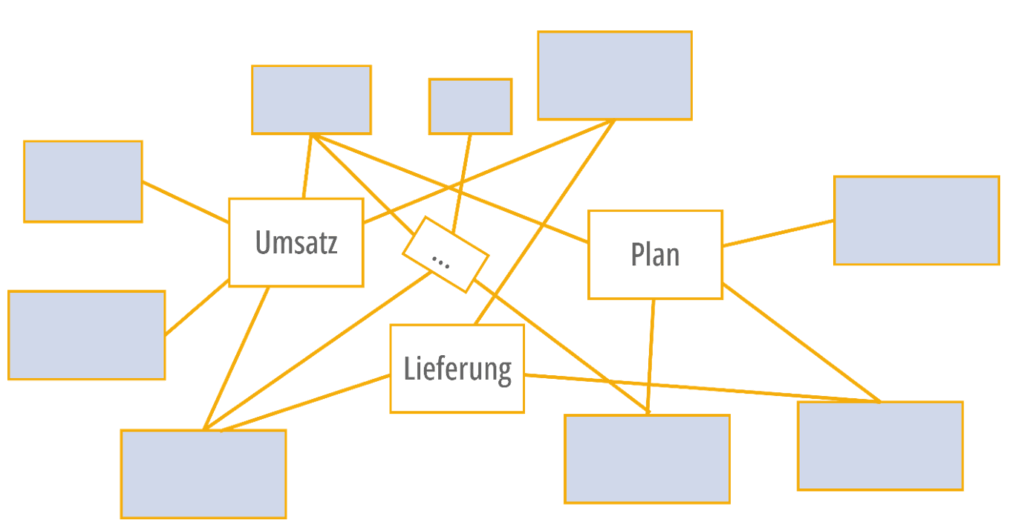
Abbildung 2: Star Schema Chaos
Zentrale Bridge statt vieler Faktentabellen
Um diese Probleme zu lösen hat Francesco Puppini eine neue Modellierungsmethode entwickelt – das Unified Star Schema (USS).
Mit dem Unified Star Schema findet ein Paradigmenwechsel statt. Data Marts werden nicht mehr nach den Anforderungen aufgesetzt, was die End User in Reports und Dashboards sehen wollen. Sondern das USS wird unabhängig von den Business Anforderungen der End User gebaut. Aber er ist darauf ausgelegt von den End Usern konsumiert zu werden. Weitere Geschäftslogiken gehören im BI Tool umgesetzt und sind nicht mehr wie bisher im Data Mart und im BI Tool hinterlegt. Das vereinfacht die Kommunikation zwischen Data Engineers und End Usern und sorgt für einfachere Wartung.
Statt immer weitere Faktentabellen für jede neu aufkommende Fragestellung zu modellieren, führt Puppini eine zentrale „Bridge“ (auch Puppini-Bridge genannt) ein, die alle relevanten Dimensionen verbindet und die Verbindungen zwischen den Tabellen verwaltet. Um die Bridge ordnen sich die Objekttabellen an (Abbildung 3).
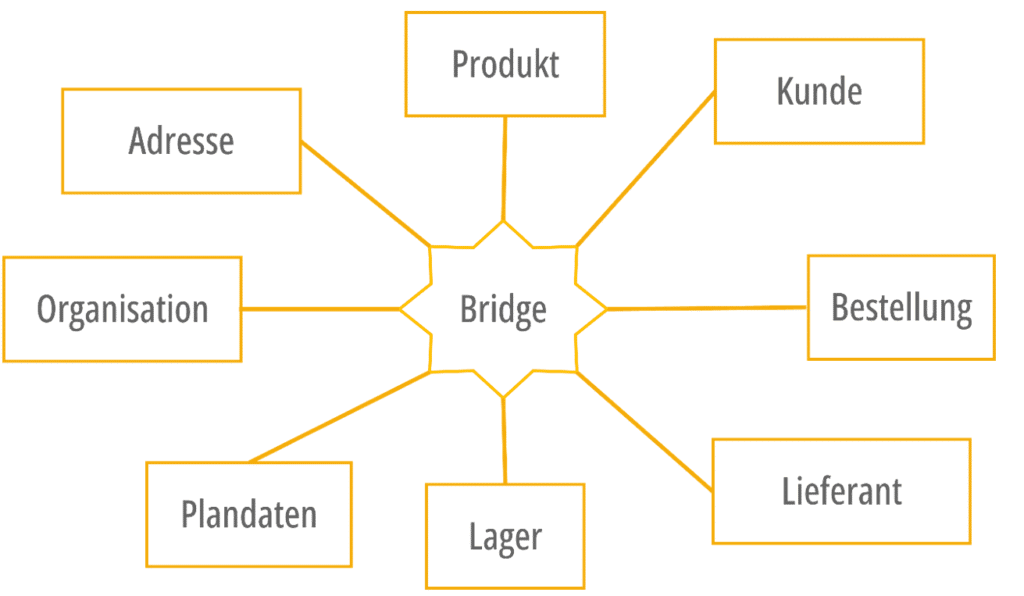
Abbildung 3: Unified Star Schema
Bei dem traditionellen Star Schema Ansatz müssten bei sechs Faktentabellen, mindestens sechs Star Schemas aufgebaut werden. Mitunter gilt es sogar dieselbe Faktentabellen in verschiedenen Granularitäten aufzubereiten. Anders verhält es sich beim Unified Star Schema. Hier gibt es nur ein Schema, egal wie viele Faktentabellen oder unterschiedliche Granularitäten es gibt. Zudem muss keine Unterscheidung zwischen Fakten und Dimensionen mehr gemacht werden.
Es gibt drei Grundprinzipien:
- Es gibt nur eine Bridge
- Messwerte stehen in der Bridge
- Attribute bleiben in den Objekttabellen
Die Bridge enthält eine „Stage“ Spalte, die angibt, aus welcher Objekttabelle die Information stammt, sowie eine Key-Spalte pro Objekttabelle und deren Messwerte. Die Tabelle wird durch einen Union (Vereinigung) aufgebaut und ist als Matrix aus Primary Keys, Foreign Keys und Messwerten aus den Stage Tabellen zu verstehen (Abbildung 4). Die Anzahl an Reihen einer Stage hat eine Aussage – beispielsweise kann die genaue Anzahl an Bestellungen ermittelt werden. Zudem werden Daten nicht doppelt gehalten, da es nur eine Bridgetabelle gibt.

Abbildung 4: Beispielhafte Bridge Tabelle
Die Objekttabellen bleiben fast identisch zum Original. Es gibt lediglich eine zusätzliche Spalte, die den Joinkey zur Bridge, enthält. Ansonsten stehen in den Objekttabellen die eigenen identifizierenden Felder und die Attribute, die ggf. gesäubert sein können.
Beim Verbinden der Bridge mit den Objekttabellen wird ein Full Outer Join Effekt erreicht, da die Bridge alle Schlüssel enthält. Jede Information ist direkt verfügbar für den End User, sodass Daten beliebig kombiniert werden können. Der End User muss am Ende nur folgendes beachten: Zunächst die Bridge einladen und anschließend die Objekttabellen, die gebraucht werden für die Analyse, per Left Join verknüpfen.
Das USS ist im Presentation Layer eines Data Warehouses angesiedelt und kann auch neben Star Schemas koexistieren.
Fazit zum Unified Star Schema
- Das USS ist leicht zu nutzen und weniger fehleranfällig
- Die Daten bleiben verständlich, da die Ursprungstabellen nahezu identisch zum Original im BI Tool nachgebaut werden können
- Das USS zeichnet sich durch eine hohe Flexibilität aus, da alles miteinander kombinierbar ist
- Drastische Reduktion von Datentransformationen: Neue Business Anforderungen und Fragestellungen können direkt im BI-Tool gelöst werden, ohne dass ein Data Engineer hinzugezogen werden muss
- Mit USS ist wirkliches Self-Service möglich
Ausblick
Das Unified Star Schema kann auch für Agentic AI ein entscheidender Faktor sein. Durch das USS wird die Abhängigkeit von komplexen Multi-Join Abfragen drastisch reduziert. AI Agents können die einfachere semantische Ebene des USS leichter verstehen und abfragen, was zu schnelleren und zuverlässigeren Erkenntnissen führt.

