Warum Data Mesh für moderne Datenarchitekturen entscheidend ist
Der Begriff Data Mesh ist in den letzten zwei Jahren immer populärer geworden – und das zurecht. Denn die zeiteffiziente Nutzung und Weiterentwicklung von Daten spielt heute eine immer wichtigere Rolle. Nutzer erwarten schnellen Zugriff auf neue Daten. Gleichzeitig wollen Unternehmen diese gezielt nutzen, effizient verarbeiten und frühzeitig auf Innovationen reagieren.
Um dieser wachsenden Nachfrage gerecht zu werden, setzen Unternehmen auf moderne Speicher- und Datenarchitekturen. Im Fokus stehen nicht nur Erweiterbarkeit, sondern insbesondere die Wiederverwendbarkeit bestehender Data-Management-Strukturen. Daten werden aus verschiedenen Quellen integriert, historisiert und für fundierte Managemententscheidungen nutzbar gemacht – oft auf Basis von Data Warehouses oder Data Lakes.

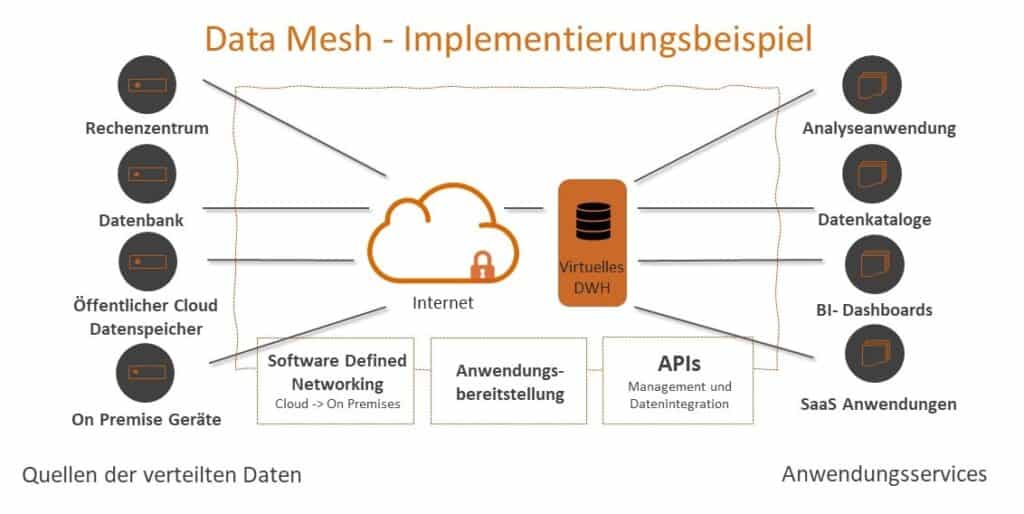
Ein Data Mesh ist eine Infrastruktur im Bereich der Datenverwaltung, die eine Konnektivitätsebene erstellt, die die Komplexität der Verbindung, Verwaltung und Unterstützung des Datenzugriffs zusammenfasst.
Das Data Mesh, dient im Kern dazu, diese Daten miteinander zu integrieren und sie als Produkt für andere zugänglich zu machen (sowohl für die Datenkonsumenten als auch für die Datenersteller). Wenn die Integrität der Daten sicher ist, bleiben auch die gespeicherten Informationen in einer Datenbank vollständig, genau und zuverlässig, komplett unabhängig davon, wann sie gespeichert wurden und wie oft auf sie zugegriffen wird.
Das domainübergreifende Nutzen von beispielsweise Userdaten innerhalb einer Organisation ermöglicht dem User bessere Anpassungsfähigkeit und somit persönlichere Angebotsvorschläge, Werbeanzeigen uvm.
Data Mesh ähnelt der Microservice Architektur. Anders als bei Microservices wird durch Data Mesh aber auch das Bearbeiten von größeren Daten schnell ermöglicht. Es ermöglicht das Lagern von Daten in virtuellen Katallogen, die mit ihren, bereits abgeleiteten Werten, für den User anwendbar sind.
Dadurch, dass der Besitz von Daten durch die Data Mesh dezentralisiert ist, werden diese zu einem zugänglichen, sicheren und lokalisierbaren Produkt, welches jetzt Teil der neuen funktionsübergreifenden Infrastruktur ist.

Auch wenn es kein vorgeschriebenes Modell gibt, sind einige Fundamente für die Implementierung des Data Mesh erforderlich. Diese unterteilen wir in vier Kategorien:
Um Probleme der Wiederverwendbarkeit und Infrastruktur vermeiden zu können, steigen immer mehr Unternehmen auf das Prinzip der Domain Ownership um.
Die Maßnahme dieses Systems, ist das Umlagern der Datenverantwortung auf die verschiedenen Fachbereiche: die Domains. Ein Unternehmen hat viele verschiedene Teilbereiche. Das Domain Ownership Design sorgt für eine flache Hierarchie und für schnellere, effizientere Datenverarbeitung.
Um den Begriff einmal etwas anschaulicher zu erklären, nennen wir folgend ein Beispiel:
Für unser Exempel nehmen wir einen beliebigen Onlineshop. Das Verbreiten der Daten auf die spezialisierten Bereiche, – in unserem Beispiel wären es die Domains: Bezahlvorgang, Warenkorb, favorisierte Items etc.- führt zu einer vernetzten, real time Daten Integration. Die Daten werden in unserem Beispiel also durch das Verteilen auf kleine, spezialisierte Bereiche in Echtzeit nutzbar gemacht. Alle Domains verwalten ihre eigenen Produkte.
Auf der graphischen Darstellung 3 lassen sich die Grundaufgaben einer Domain erkennen. Jede Domain verarbeitet ihre Daten selbständig, um sie als ein Produkt im gesamten Paket anderen zu präsentieren und anderen Usern zur Verfügung zu stellen.
Sie werden dabei von der Self-Service Struktur, welche vom Data Team gestellt wird, unterstützt.

Wenn wir über die traditionelle Datenspeicherung und Verwaltung nachdenken, stellen wir uns eine große Ansammlung von Daten vor. Diese Daten müssen von einem zentralen, spezialisierten Team verarbeitet werden, damit sie für die Nutzer überhaupt nützlich sind. Die Teams müssen somit ständig mit einer großen Menge an Daten umgehen. Hierbei sind die Quellen der Informationen voneinander isoliert.
In der Data Mesh Struktur hat das Data Team im Gegensatz dazu nur eine unterstützende Aufgabe, da die eigentliche Datenverarbeitung wie oben bereits erwähnt, nun von den Domains selbst übernommen wird. Dies wird durch eine vom Data Team erstellte Infrastruktur arrangiert. Diese Infrastruktur ermöglicht den Nutzern analytisches Datenmanagement mit Self-Service-Funktionen. Das zentrale Data Team wird so entlastet und wirkt eher unterstützend. Das Team verbindet ursprünglich isolierte Daten und assistiert dem Unternehmen bei dem Übergang zu automatisierten Analysen von Daten in großem Maßstab. Jede Domain behält somit die Rechte für ihre Daten.
Dies verhindert eine monolithische Anwendungsarchitektur (siehe Abbildung 3), da Daten in eine Sammlung von Funktionen und Messwerten zerlegt werden können, die unabhängig von den anderen erstellt, gewartet und verbessert werden.

Um das Ziel erreichen zu können, die Verantwortung für spezifische Daten, dem jeweils dafür spezialisierten Bereich zu überlassen und auf ein zentrales, spezialisiertes Team zu verzichten, müssen wir in der Lage sein, Daten nicht nur als Messwerte, sondern auch als eigenständige Produkte zu definieren. Diese Datenprodukte aggregieren alles, was ein Datenkonsument benötigt, um aus den Daten der Geschäftsentitäten einen Mehrwert abzuleiten.
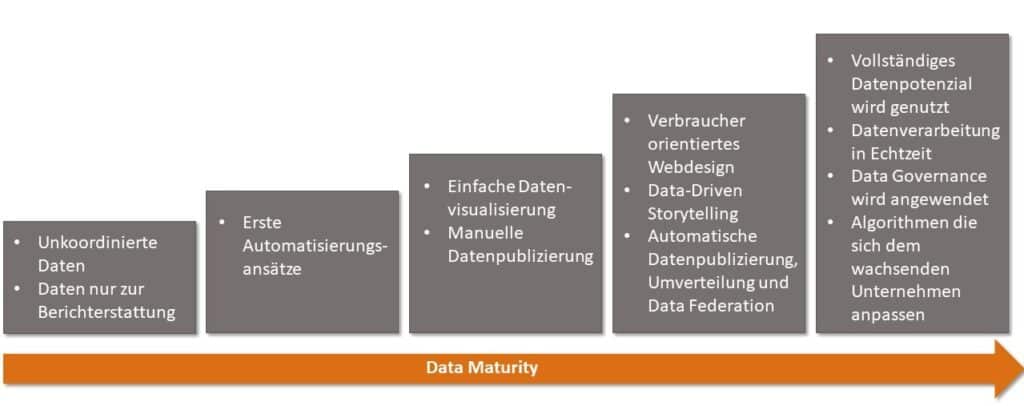
Wenn ein Unternehmen Daten als Produkt statt Nebenprodukt sieht, ist ein Grad der Data Maturity erreicht. Ist dieser Grad erreicht und die Organisation groß genug, um von dem Modell profitieren zu können, so kann Data Mesh die richtige Optionein.
Unten haben wir ein Data Maturity Diagramm aufgeführt, das die einzelnen Schritte zur effizienten Datennutzung erklärt. Für das richtige Unternehmen ist Data Mesh definitiv eine neue, schnelle Art der Datenspeicher- und Verarbeitung und ermöglicht somit einen Zeitgewinn, welcher einen klaren Vorteil am Markt schafft.