Confluent Kafka als Enabler für die Kappa-Architektur: Real-Time und Analytics vereint
Eine Kombination von zwei Welten (Integrationsansätze)
Schon lange sind Pipelines in Form von ETL und ELT im Bereich des Data Engineering gang und gäbe. Ich schreibe Datenintegration in einer Vielzahl von Varianten. Sei es mithilfe von Low-Code Applikationen wie Talend, Self-Code mit Python oder andere Microservices mit Java. Meine Pipelines laufen zum Beispiel alle paar Stunden oder Minuten. Vielleicht laufen meine Pipelines, weil sie z.B. durch einen Webhook ausgelöst werden. Aber wir sind weiterhin in der Welt der Batches und das ist auch völlig in Ordnung. Vielleicht besagt gar die Anforderung in Form von Batches zu integrieren, vielleicht bedarf es regelmäßig eines Fullloads in seiner Gesamtheit, vielleicht kann es die Quelle auch nicht anders zur Verfügung stellen.
Auf der anderen Seite gibt es auch Quellen, die eventbasiert Daten zur Verfügung stellen, sowie Ziele, die in Real-Time oder Near-Real-Time die Daten benötigen. In einigen Varianten habe ich das auch in gemischter Form. Doch wie verheirate ich diese Form der Integration?
Die Antwort: mit einer Kappa-Architektur.
Kappa Architektur
Der Kerngedanke von dieser Architektur ist, dass man Real-Time und Batch-Prozesse bedienen kann und das mit nur einem Technologie-Stack. Entscheidend ist die Real-Time Schicht. Diese Schicht ist in der Lage zwei Ziele unabhängig voneinander zu bedienen: Einen Real-Time Abnehmer, wie zum Beispiel Flink, Spark oder andere Formen von Message Konsumenten, sowie einen Permanent Storage, wie zum Beispiel Datenbanken für analytische Zwecke.
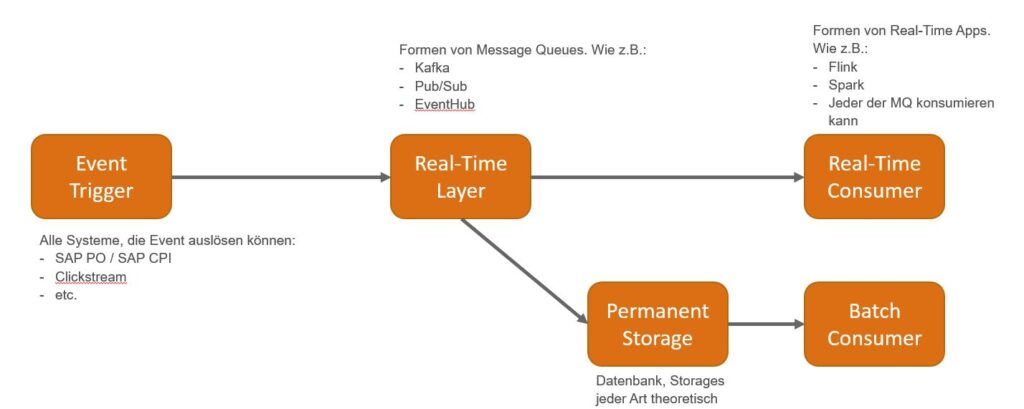
Die Vorteile dieser Architektur:
- Ich kann beide Welten bedienen: Real-Time und Batch!
- Nur eine Real-Time Infrastruktur ist erforderlich
- Der Fokus liegt auf Real-Time
- Keine Inkonsistenzen zwischen Real-Time Abnehmer und dem Permanent Storage
- Auch wenn es mehrere Quellen geben kann, die sowohl per Batch als auch eventbasiert triggern, laufen die Daten dennoch durch die gleiche Schicht. Es gibt einen definierte Single Point of Truth!
- Die Architektur ist leicht erweiterbar. Sowohl Storage als auch Real-Time Abnehmer können ergänzt oder ausgetauscht werden.
Abgrenzung zur Lambda-Architektur
Die Lambda-Architektur verdoppelt die Anzahl von Integrationsschichten. Sie sieht vor, dass es sowohl die Real-Time Schicht gibt als auch die Batch-Schicht. Ich habe hier also im Zweifel zwei unterschiedliche Quellcodes und/oder sogar zwei Technologien sowie zwei Infrastrukturen zu pflegen. Außerdem muss ich dafür sorgen, dass es keine Inkonsistenz zwischen den beiden Datenflüssen gibt.
Umsetzung von Kappa mit dem richtigen Stack
Um direkt mit den Buzzwords zu starten: Eventbasierte Daten mit Kafka, Kafka Streams und Snowflake.
Die Daten, die meine Prozesse erzeugen, sollten im Idealfall direkt nach Kafka wandern. Kafka bietet mir als de-facto Industrie-Standard für Data Event Streaming eine skalierbare Infrastruktur, um meine Daten schnell an meine Abnehmer zu liefern. Kafka Streams bietet mir nun die Möglichkeit mit meinen Daten zu arbeiten, um diese zum Beispiel zu bearbeiten, zu filtern, zu aggregieren oder diese mit anderen Quellen zu joinen. Das Ergebnis dessen kann dann von meinem Abnehmer in entkoppelter Art und Weise konsumiert werden.
Zu guter Letzt nutze ich die Cloud-Datenbank Snowflake als Sink. Unter Sinks verstehen sich Anbindungen, die ausschließlich Daten abladen. Snowflake ist nicht nur für analytische Zwecke hervorragend geeignet, sondern kann auch mit großen Datenmengen umgehen.
Doch wie kann ich diese umfangreiche Infrastruktur skalierbar bei mir umsetzen? Ein erprobter Ansatz ist die Nutzung von Confluent Cloud. Mithilfe eines cloud-nativen Kafka schafft Confluent nicht nur das perfekte Real-Time Layer für meine Kappa-Architektur, sondern bietet on-top noch mithilfe des Stream Designers eine GUI gestützte Applikation, um Kafka Streams aufzusetzen. Alternativ kann ich auch mithilfe von der Confluent eigenen ksqlDB eine Stream Pipeline aufsetzen.
Zum Schluss kann ich auch durch die Vielzahl von Kafka Sink Connectors eine einfache Einrichtung vornehmen, um meine Quellen an die Snowflake anzubinden. Die Daten werden nun dauerhaft in Snowflake für analytische Zwecke oder Batch-Belieferung zur Verfügung gestellt.
Ein Beispiel-Szenario: Ordertracking für den Webshop und dem DWH am Beispiel von confluent Kafka
Stellen wir uns vor, wir haben ein ERP-System in dem wir unsere Aufträge, Lieferungen und Rechnungen verwalten. All diese Prozesse werden natürlich von viele Anwendern bedient und auch teilweise durch automatisierte Prozesse bearbeitet.
Diese Daten sollen für das Ordertracking schnell dem Kunden im Shop dargestellt werden. Aber gleichzeitig ist auch die Erwartung, dass dieselben Daten für Auswertungen im DWH zur Verfügung stehen.
Und hier schließt sich der Kreis. Die Daten werden also eventbasiert in Richtung Kafka geschickt. Wir haben zum Beispiel vier Topics, also Kafka-Datentöpfe – Auftragskopf, Auftragspositionen, die Lieferung und die Rechnung. Dort kann ich nun entscheiden, ob die Daten in ihrem Schema für den Webshop ausreichen, oder ob diese noch angereichert, reduziert oder gefiltert werden müssen. Vielleicht wünsche ich auch alle Töpfe für den Shop bereits zu joinen. Dafür würde ich Kafka Streams zum Beispiel einsetzen. Der Shop erhält also perfekt vorbereitete Daten und das auch noch in wirklich kürzester Zeit. Der Nutzer des Webshops ist damit schon einmal zufrieden.
Nun muss noch das DWH bedient werden. Lasst uns weiter mit dem Beispiel Snowflake vorgehen. Ich muss ein paar Vorkehrungen, wie zum Beispiel Nutzer und Rechte, in der Snowflake treffen, aber danach kann ich direkt einen Fully-Managed Kafka Sink Connector von Confluent einsetzen. Die Einrichtung dauert wenige Minuten. Die Kafka Topics sind ausgewählt und liefern direkt die Daten in eine von Confluent definierte(n) oder von uns vorgegebene Tabelle(n). Der Connector liefert nun die Daten passend für eine OLAP Datenbank portioniert in Micro-Batches.
Jetzt kann dem DWH Team überlassen werden, wie sie die Daten modellieren. Alle Daten, wie Key, Value und Header (darunter tech. Timestamps) stehen automatisch zur Verfügung.
Wir haben mit dieser Architektur gezeigt, dass mithilfe einer Technologie zwei Abnehmer bedient werden können, ohne dass der eine vom anderen abhängig ist. Wir haben auch gezeigt, dass wir zwei unterschiedliche Ziele mit Daten beliefern können und dabei beide Anforderungen erfüllen. Das heißt zum einen für den Webshop konforme Daten und für das DWH möglichst Quell-nahe Daten in ihrer Ursprungsform. Unsere Kappa-Architektur steht!
Ich habe Ihr Interesse geweckt? Dann nehmen Sie gerne mit uns Kontakt auf.
Jetzt registrieren und keine Veranstaltungen mehr verpassen.